
Fewer systems. Less complexity. Same Postgres.
I recently gave a talk at POSETTE 2026 titled “The Rise of PostgreSQL as the Everything Database.”
This post is the short version of that talk.
The idea is not that Postgres should replace every database, cache, search engine, warehouse, or vector store.
The idea is sharper than that:
Stack complexity is the real problem.
PostgreSQL is becoming the place where more application workloads naturally start: transactions, JSON, search, geospatial, vectors, scheduled jobs, time-series patterns, and AI application data.
Not because Postgres is perfect at everything.
Because the alternative has become too expensive.
The hidden tax of “just add another system”
For years, every new data problem came with a familiar answer.
Need documents? Add a document database.
Need cache? Add Redis.
Need streaming? Add Kafka.
Need search? Add Elasticsearch.
Need vectors? Add a vector database.
Need analytics? Add a warehouse.
Each system solved a real problem. But each one also created another boundary. And every boundary created a bill.
Data movement is not just ETL.
It is duplicated schemas, stale data, broken pipelines, security drift, inconsistent permissions, different monitoring surfaces, different backup models, and different failure modes.
At some point, your architecture diagram stops being a design.
It becomes a scavenger hunt.
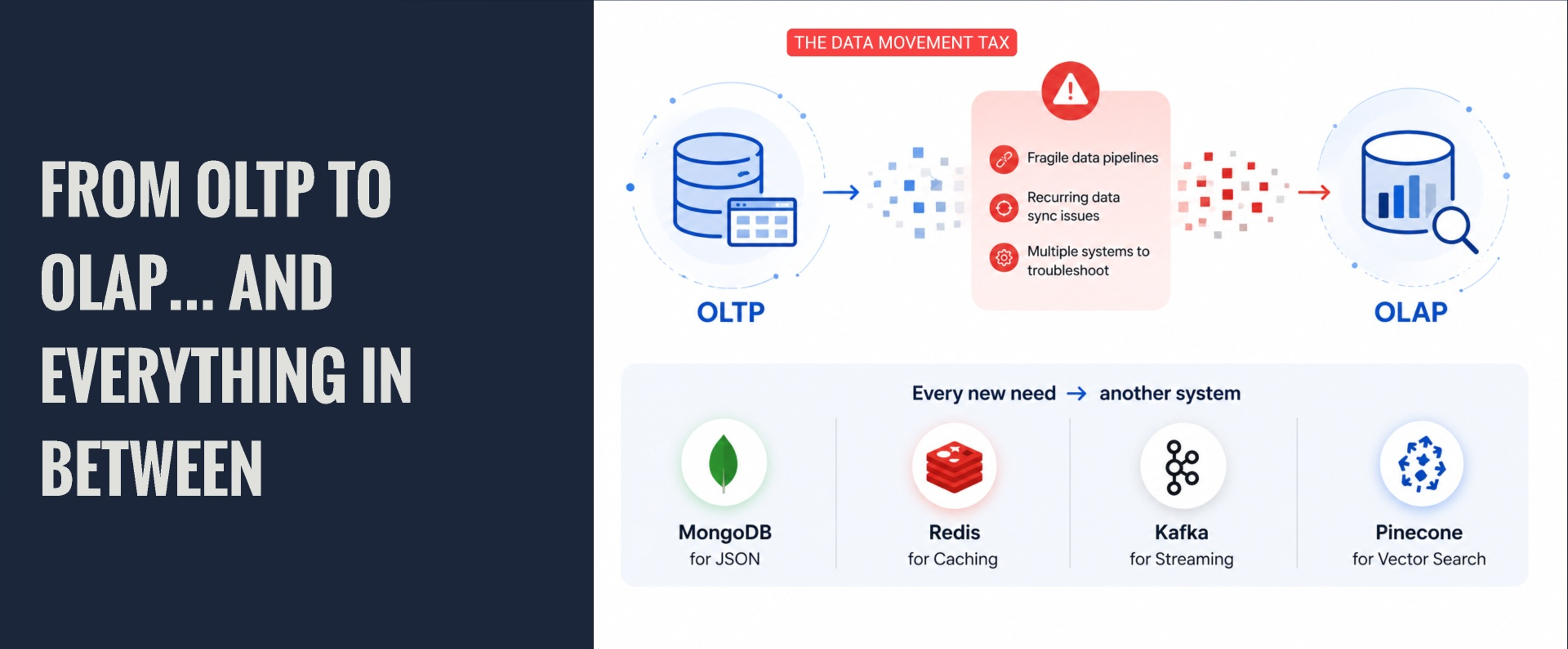
Most time is not spent building
This is the part production teams feel every day.
Where is my data?
Which system is the source of truth?
Why is the search index stale?
Why does the dashboard not match the database?
Who owns this pipeline?
Why did this CDC job fail again?
Most of the time is not spent building. It is spent navigating pipeline complexity.
That is the real cost of fragmented systems.
Not only the cloud bill.
The human bill.
The cost paid in developer time, operational drag, and meetings where everyone agrees the architecture is “temporarily complicated.”
And nothing is more permanent than temporarily complicated.

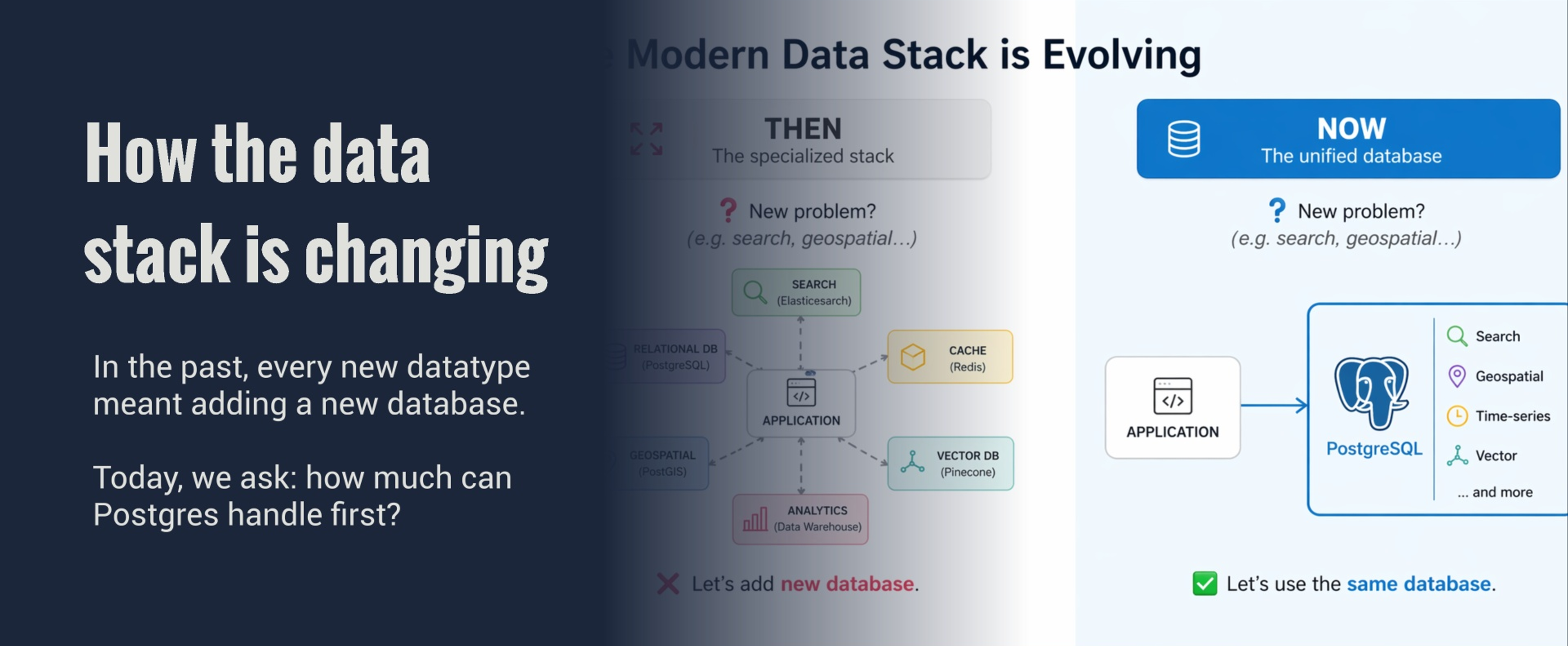
The data stack is changing
The old question was: What new database should we add?
The new question is: How much can Postgres handle first?
That shift matters.
It does not mean Postgres should replace every specialized system.
It means specialized systems should earn their place.
Consolidate by default.
Specialize Deliberately.
Use a dedicated search engine when search complexity demands it.
Use a dedicated vector database when vector scale or latency demands it.
Use a warehouse when analytics scale and governance demand it.
Use Redis when cache semantics demand it.
But do not add systems by reflex.
Every new system should answer one uncomfortable question:
Is the benefit of specialization greater than the cost of moving, duplicating, securing, governing, and operating the data somewhere else?
Often, the answer is no.
And that is where Postgres enters the conversation.
The unified-data instinct is winning
There is a visual in my deck that captures this perfectly.
On one side: a developer pushing a cart full of systems — search, cache, vector DB, analytics, events, graph, streams.
On the other side: Postgres.
The caption says it all: Fewer systems. Less complexity. Same Postgres.
That is not anti-specialization.
It is anti-unnecessary-specialization.
A simpler stack is easier to secure, observe, recover, explain, and debug.
And every experienced engineer knows this: the best architecture is not the one with the most logos.
It is the one that survives production.

Today, architects are increasingly asking whether the existing database can handle the next workload before adding another moving part.
That is the unified-data instinct.
And Postgres is benefiting because it has the right foundation: relational core, SQL, transactions, indexes, JSON, extensions, mature tooling, and developer trust.

The architect’s new core question
The most important question in the talk was not:
“What can Postgres do?”
It was this: “What can I stop synchronizing?”
That question changes the architecture conversation.
Synchronization is where systems become expensive.
It is where freshness breaks.
It is where ownership blurs.
It is where security drifts.
It is where one source of truth slowly becomes five partial truths wearing a trench coat.
If Postgres can keep a workload close to the data, you avoid an entire class of problems.
That is the real win.
Extensibility is PostgreSQL’s secret weapon
Postgres is not just one database.
It is a database platform.
That sounds like marketing until you look at how it actually works.
Postgres was designed for extensibility: new data types, functions, indexes, operators, procedural languages, and extensions.
That is why the ecosystem keeps absorbing adjacent workloads.
<div class=”pg-quote”> Postgres does not need to become ten different products. <br><br> It lets the ecosystem teach it new tricks. </div>
The center stays stable.
The edges keep expanding.

The everything database pattern
This is where the idea becomes practical.
- JSONB means flexible schema does not automatically require a separate document database.
- Full-text search means many search workloads can stay where the data already lives.
- pgvector means embeddings can live next to application data, metadata, permissions, and SQL filters.
- PostGIS means location data can join the rest of the business.
- pg_cron means scheduled database jobs do not always need another scheduler.
- TimescaleDB means time-series is now very much a Postgres conversation.
Even caching deserves a more thoughtful question.
Should Postgres replace Redis everywhere?
No.
But does every simple cache-like use case need Redis?
Also no. “A cache is not free just because it is fast. “
The pattern is the same every time:
Do not leave Postgres by default.
Leave when the workload earns it.
AI made this obvious
AI applications made the data movement tax impossible to ignore.
A simple RAG app can quickly become a distributed data puzzle: source documents here, chunks there, embeddings somewhere else, metadata in Postgres, permissions in the app, search in another index, freshness in a pipeline.
That is a lot of architecture before the user even asks a question.
With pgvector, embeddings can live in Postgres next to application data, metadata, permissions, and SQL filters.
That does not mean every vector workload belongs in Postgres.
It means the default AI architecture should not be “split everything immediately.”
AI did not eliminate data architecture. It made bad data architecture more expensive.
For many AI apps, the hard part is not storing vectors.
The hard part is grounding those vectors in trusted, fresh, permission-aware business data.
That is a Postgres-shaped problem.
So what does “Everything Database” really mean?
It does not mean one database for every workload forever.
That would be lazy architecture wearing a Postgres hoodie.
It means Postgres has changed the default question.
The old instinct was: “Every new problem needs a new system.”
The new instinct is: “What can I keep in Postgres?”
That is the shift.
Postgres has the relational foundation.
It has the extension ecosystem.
It has developer trust.
And it has enough practical capability to collapse many workloads back toward the center.
What can I stop synchronizing? That is the question And more often than before, the answer is: Keep it in Postgres.Fewer systems. Less complexity. Same Postgres.
That is the rise of PostgreSQL as the Everything Database.
Watch the POSETTE talk
This post is based on my POSETTE 2026 talk:
The Rise of PostgreSQL as the Everything Database
YouTube: https://youtu.be/nmgj7oufNo8
POSETTE speaker page: https://posetteconf.com/speakers/varun-dhawan/
Huge thanks to the POSETTE team and the broader Postgres community for creating space for this conversation.
References
Views are my own. I work on PostgreSQL in the cloud, but this post reflects my personal view as a database person who has seen enough “just add one more system” decisions eventually send a bill.









