
Average(mean), median, mode are core statistical concepts, that are often applied in software engineering. Whether you are new to programming or have multi years of computer science experience, you’ve likely at some point in time will have used these statistical functions, say to calculate system resource utilization, or network traffic or a website latency. In my current role, my team is responsible for running a telemetry platform to help dev teams measure application performance. We do this by collecting point-in-time data points referred as metrics.
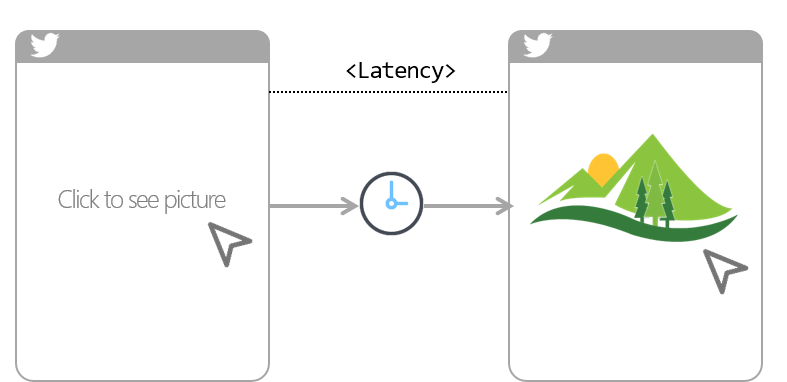
A common use case for metrics is to tell the application latency (i.e. amount of time it took between a user action and web app response to that action). For examples, amount of time it took you to click on twitter photo and till it finally showed up on your device screen. So if you have this metrics collected at regular intervals (say every 1s), you can simply average it over a period of time like an hour or a day to calculate latency. Simple right!
Continue reading “Why Averages suck and what make Percentiles great”
