
This is 3rd post in my series featuring Window Function in PostgreSQL. In this post, I’ll explain how to use Ranking window functions – that we can use to calculate various aggregations such as Row Number, Rank, and Dense Rank within each window or partition.
Continue reading “Data Science with PostgreSQL – Ranking Window Functions”Data Science with PostgreSQL – Aggregate Window Functions
Here we go, after weeks for procrastination finally the 2nd post in my series featuring Window Function in PostgreSQL. In this post, I’ll explain how to use Aggregate window functions – that we can use to calculate various aggregations such as average, counts, minimum / maximum values, and sum within each window or partition.

Data Science with PostgreSQL – Window Functions Basics
Window functions are a powerful tool that helps to leverage the power of PostgreSQL for Data Analysis. In this blog series, I will explain what window functions are, why you should use them, types of window functions and finally will introduce you to some basic window functions in PostgreSQL. In the next few post, I’ll go through more advanced window functions and demo some scenarios. So let’s get going.

2021 – My Year in Books 📚

This year was anything but normal. In the beginning, I had no idea how the next 12 months would play out the way that they did, and books are one of the things that helped me get through this year.
I spent a lot less time driving to work, eating lunch in the office, and doing groceries. And I used this time to read (and watch some amazing documentaries) that gave me a better perspective of our world.
Continue reading “2021 – My Year in Books 📚 “Fixing spotty internet using Mesh Wi-Fi
TL;DR - having slow internet speed due to Wi-Fi dead zones - consider upgrading to Mesh Wi-Fi network.
Have you ever experienced great Wi-Fi connectivity in one room of your home, while the internet is almost dead in other? Or your Zoom calls keep dropping forcing you to move from one room to another in search for better signal strength. I hear you, I’ve been there and you definitely are not alone.

Spotty home Wi-Fi are nightmare, especially right now when everyone is WFH. Luckily there’s an easy fix? “Mesh Wi-Fi“!
Continue reading “Fixing spotty internet using Mesh Wi-Fi”Recursive SQL for querying hierarchical data: Part 2 – Levels and Ancestors

Ok, so you’ve stored hierarchical data in a relational database, and written recursive CTEs to query the data and find relationships. Now the application team wants to query hierarchical levels and print the complete ancestry tree. Time to deep dive into some advance CTE constructs.
This is the second post of the series about the Recursive SQL for querying hierarchical data started in the previous post . If you haven’t read it already, I recommend reading it to understand the key concepts:
- What is a hierarchical data?
- How to store hierarchical data in a relational database?
- And how to query hierarchical data using:
Self-JoinsCommon Table Expressions (CTE)
In this post, we’ll discuss the advanced scenarios like displaying hierarchical levels and printing the “ancestry tree”. Let’s dive in…
Continue reading “Recursive SQL for querying hierarchical data: Part 2 – Levels and Ancestors”Recursive SQL for querying hierarchical data: Part 1

Recently, I was working on an application that required reading hierarchically structured data. And I thought it might be useful to document multiple ways to store and query such hierarchical data (ex. Org. chart, File-system layout, or Set of tasks in a project) in a database. So, let’s jump right in.
Definitions first – what is hierarchical data?
Hierarchical data is a specific kind of data, characterized by a hierarchical relationship between the data sets.
Think about data sets having multiple levels: something above, something below, and a few at the same level. A typical example of such hierarchical model is an organizational chart like the one below.
Continue reading “Recursive SQL for querying hierarchical data: Part 1”PostgreSQL – how to UPSERT (Update or Insert into a table)
Most modern-day relational database systems use SQL MERGE (also called UPSERT) statements to INSERT new records or UPDATE existing records if a matching row already exists. UPSERT is a combination of Insert and Update, driven by a “PRIMARY KEY” on the table.

Why Averages suck and what make Percentiles great
Average(mean), median, mode are core statistical concepts, that are often applied in software engineering. Whether you are new to programming or have multi years of computer science experience, you’ve likely at some point in time will have used these statistical functions, say to calculate system resource utilization, or network traffic or a website latency. In my current role, my team is responsible for running a telemetry platform to help dev teams measure application performance. We do this by collecting point-in-time data points referred as metrics.
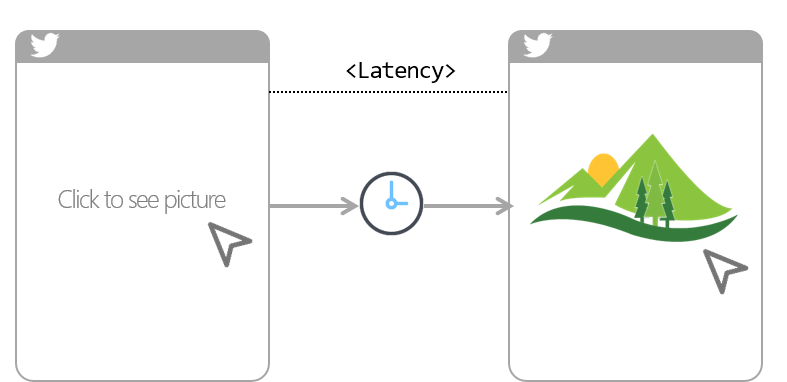
A common use case for metrics is to tell the application latency (i.e. amount of time it took between a user action and web app response to that action). For examples, amount of time it took you to click on twitter photo and till it finally showed up on your device screen. So if you have this metrics collected at regular intervals (say every 1s), you can simply average it over a period of time like an hour or a day to calculate latency. Simple right!
Continue reading “Why Averages suck and what make Percentiles great”2020 – My Year in Books 📚

I don’t think there has been a better year than 2020 to read. With most of us confined to our homes at some point during the year due to pandemic, books (and Netflix!) have become more popular than ever.
In this post, I’m reviewing all the books I have read in the year. Hopefully you’ll enjoy these quick reviews, plus I’ve also added a favorite quote from each.
In no particular order- let’s go!
Continue reading “2020 – My Year in Books 📚”